INDEX
- §1 通用思路
- §2 快速归档
- §3 归档整体流程(完整归档 & 快速归档)
- §4 准备阶段
- §4.1 确认归档表
- §4.2 思路:确认归档数据范围 & 归档方案待选(重点)
- §4.3 归档方式选择 & 业务场景覆盖
- §4.4 确认归档数据范围 & 确认归档方案(快速归档可以直接从这里开始)
- §4.5 迁移工具与方案
- §4.6 生成归档迁移执行计划
- §5 迁移执行阶段
- §6 验证阶段
- §7 擦除阶段
§1 通用思路
数据归档就是把一坨数据挪走,换一个地方存放,然后把原来的数据干掉
数据移走后,不能影响现有业务的使用,需要继续保留被更新的能力(不存在完全冷掉的数据)
干掉原数据时要避免影响正常业务,主要是避免引起波动
但需要注意:数据归档不应该作为解决问题的首选方案
§2 快速归档
每次归档前,应该优先考虑能否快速归档
- ==快速归档条件下,只需要考虑把那些表中哪些数据截转走,然后清理原数据即可 ==
- 不需要考虑所有使用场景和极端特殊情况,不是从0开始不考虑,而是早就处理完了
- 不需要考虑归档后数据再遇到更新诉求时的自动更新,不是直接不考虑,而是已经具备了
- 首次归档时,尽量建立快速归档能力(归档这个事不可能是一次性的,但不可强求)
快速归档几乎 不可能是首次归档时的首选方案,具有如下前提
- 截转数据不影响现有功能
- 不会出现<必须使用归档数据>的业务,即使有也已经支持了
- 全量数据已保存多份(比如es)且充分在各个查询业务中承担职责(数据切走后,逻辑不会崩)
- 归档数据极少修改诉求,极少是指可以轻松通过工单或运维功能完成归档数据更改的量,其他场景现有业务已经支持
- 归档环境健全
- 最好归档数据历史上归档过,直接复用归档过程中的数据处理方式(原样存、合并、计算等)
- 可以复用上次的归档工具、验证方法
当前归档不满足快速归档的前提条件时,需要按下面完整流程评估准备工作
通常,准备工作涉及业务实现方式的调整,需要较长时间,这个步骤定义为 业务场景覆盖
直接的说就是决定业务数据会归档到哪里去,以及如何与原数据的兼容
§3 归档整体流程(完整归档 & 快速归档)
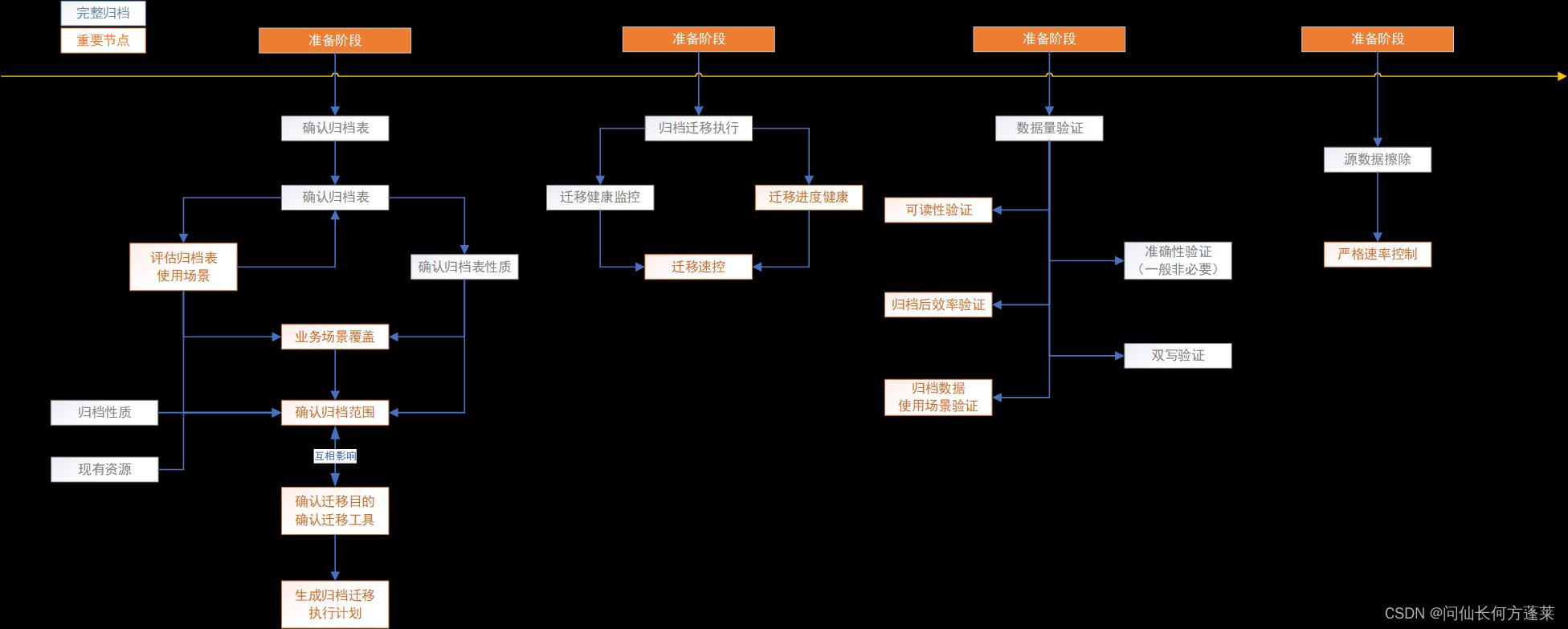
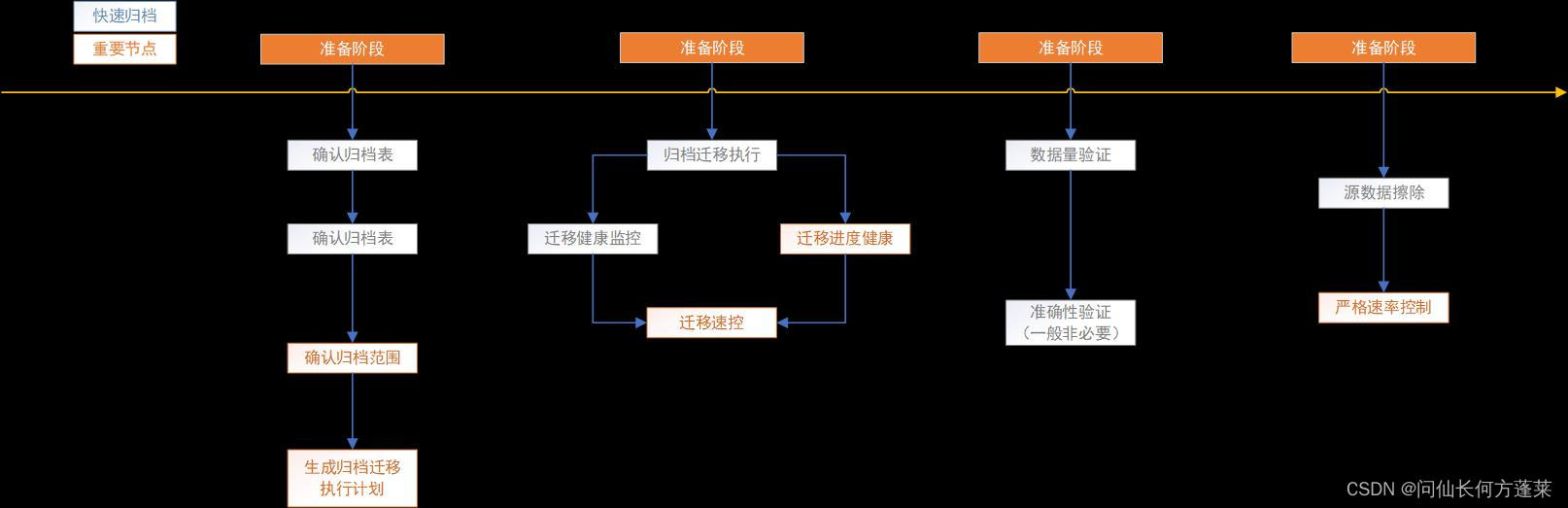
数据归档实施流程如下,<快速归档>主要节省了<准备阶段>需要花费的精力:
完整归档流程
快速归档
§4 准备阶段
§4.1 确认归档表
完整确认归档表实践参考 【方案实践】数据归档-order
需要考虑归档的依据:
- 以解决慢处理为目的
- 优先处理慢查询本身,然后考虑低成本变更业务实现方式,如果可以实现就不优先考虑以归档为首选方式
- 已经优化,但效果不理想,或达不到压测、性能指标的
- 可以优化,但从数据增长趋势考虑,短期内依然有性能危险的
- 无所谓优化,数据量达到非常危险的程度的
- 以清理磁盘为目的
- 优先考虑扩容
- 优先考虑归档非业务主数据,然后考虑归档占数据量多的
磁盘占用与数据量方面,可以参考下面 sql,查询结果实例如下
注意:磁盘占用 = size + idxsize
select
table_name,
table_comment,
table_rows,
CEILING(data_length / 1024 / 1024) size,
CEILING(index_length / 1024 / 1024) idxsize
from
information_schema.TABLES
where
TABLE_SCHEMA = 'order'
order by
size | table_rows desc

§4.2 思路:确认归档数据范围 & 归档方案待选(重点)
初步确定归档表后,需要按下面逻辑顺序评估归档数据范围
快速归档主要省略这里需要花费的精力
明确本次归档主要目的
- 清理磁盘空间:优先归档几乎没用但占地方的数据,日志、操作记录
- 解决慢 sql、慢业务:优先解决目标涉及的数据,必要时可以归档临近终态的数据
- 闲着没事优化、重构、项目优化等
完整的梳理业务场景
- 哪些项目、公共组件使用了归档表
- 使用场景分别是什么
- 简单查询
- 关联查询
- 统计查询
- 分页
- 更新:数据还不能视为终态,但终态数据本身几乎就是伪命题
- 数仓抽数
- 定时任务爬表
明确各个场景出现频次
- 频繁逻辑:有些场景下,归档前需要做业务逻辑的调整,逻辑出现频繁可能导致这里成本变高
- 频繁调用:显著加剧慢业务影响,比如一个 10 秒慢 sql,每小时一次调用可以接受,一分钟一次就不行了
明确各数据性质
- 业务主数据:即流程性数据
- 轨迹数据:即周期性数据 + 临时性数据,都可以体现业务主数据的变迁轨迹
- 周期性数据存在时:虽然不推荐,但对应的临时性数据可以忽略,即不归档直接清理
- 仅临时性数据存在时:若数据可以体现业务主数据变迁轨迹,则升格视同周期性数据,否则虽然大多数场景下不推荐,但是可以删
整理可用归档目的地
- 同库同构表
- 异库表
- es
- monogo
- prometheus/prms
- 数仓
- oss
梳理可用的归档行为
- 全量归档:独立归档,所有字段基本原样归档,常见于业务主数据
- 关键信息归档:独立归档,舍弃时效性极强的字段,将关键信息归档,常见于轨迹数据
- 关联覆盖归档:独立归档,多个表间关联,但都需要归档,且归档存储介质、归档目的地可以相同,则将多表按统一的业务逻辑关联关系归档。统一业务逻辑关联关系通常是一个统一的时间。虽然通常可以实现最小业务修改,但始终不推荐
- 宽表归档(数据横向合并):不独立归档,若干维度数据联合归档,多见于带有管理端花样查询、统计查询场景的数据
- 归并归档(数据纵向合并):不独立归档,但做多条合并,常见于轨迹数据归档,要求查询场景很有限且要求不高
- 深度加工归档:不独立归档,涉及字段值的映射、计算、合并、统计,场景特殊,尽量避免
上述归档行为均有各自适合的场景,但存储条件允许的前提下,能不删减信息就不删减信息,能不改变数据结构就不改变数据结构
归档数据划分与思路指导
使用方式
- 以 慢处理 为主要目的时
- 应优先考虑解决慢处理本身,慢处理是因数据量过多导致而不能优化时,才考虑归档
- 普遍慢的话另行别论,解决慢处理获得成果可能比归档代价还大
- 例:A数据的简单查询慢,可以优化吗,如果不能我应该从哪些角度考虑归档
- 单纯以 清理磁盘 为目的时
- 优先清理已过失效性的轨迹数据
- 准备归档的数据分别遇到下面场景时,分别需要注意什么,综合起来要怎么归档

归档数据范围的划分,按时间范围截断,通常原库中保留 2/3/6 个月数据,其余归档走。
具体时间需要综合考虑数据量和归档目的
- 解决慢处理时
- 统计各个级别保留和迁移走的数据量,count 不可用时可以使用 id 估算
- 预估一下最多保留多少数据时,可以达到解决慢处理的目的,保留数据可以参考下表
- 尝试迁移较少数据,验证迁移效果,如果结果不理想,可以考虑二段迁移
- 归档对于业务影响不大时,可以一次稍微多迁移一些,但务必保证业务正常
| 简单场景 | 复杂场景 | |
|---|---|---|
| 业务主数据 | 千万级数据不影响使用,以实测为准 | 需要参考历史数据估算效果 |
| 轨迹数据 | 亿级数据不影响使用,以实测为准 | 可以在归档后验证,如有必要进行二次归档 |
例:库中保留 6/3/2 个月数据时,依次剩余 5000w、3000w、2000w 数据,预计 4000w 数据量时慢处理可以改善。可以先迁移6个月前的数据并验证,如果不够理想再次迁移3个月数据观察效果。
- 清理磁盘时
- 统计各个级别保留和迁移走的数据量,可以使用 count 或用 (id 范围/步长) 估算
- 预估迁移数据大小 = 预计迁移数据量 * information_schema.TABLES.AVG_ROW_LENGTH
- 由磁盘占用比较突出的几个表凑够希望腾退的磁盘空间即可
§4.3 归档方式选择 & 业务场景覆盖
业务场景覆盖时应该考虑
- 完全覆盖业务场景
- 尽量少业务兼容性调整
- 尽量少数据结构变化
- 在精力允许的情况下,尽量考虑扩展性(只要项目开始归档,就一定不是一锤子买卖)
业务场景覆盖时常用方案
- 全量切换数据源
- 完全切换新的数据源读数据,用于数据全量备份的场景,比如全量存了 es
- 双读
- aop 方式:先本地读,查无数据后归档读
- 接口路由:提供两个读实现,一个读原始库,一个读归档库,可以按一定路由策略自动路由(需要业务场景支持)
- 降级:归档读作为本地读的降级方案(反过来可以作为业务场景覆盖阶段的测试手段)
- 双写
- aop方式:本地写,同时归档写
- 异步:同步本地写,扔异步归档写的消息等
- 监听binlog:同时保留归档单表与宽表
- 数据存在校验:可以直接区分出不存在的数据,存在的作为本地写,不存在可以具体问题具体分析
- 直接在业务场景上区分
- 在操作端直接区分现数据查询和归档数据查询,比如查询历史数据复选框
- 业务实现方式变更
- 多表关联 -> 单表多次查询
- 分页 -> 取消不必要的分页(比如轨迹数据,前端分页即可)
- 业务上实现方式的调整,同步->异步、扫全表->爬表、大驱动表->小驱动表、主动查询->被动消费、全数据检查->有效数据提取
业务场景覆盖阶段的衍生需求以及验证
- 可读性验证:新的读方式可以正常获取数据
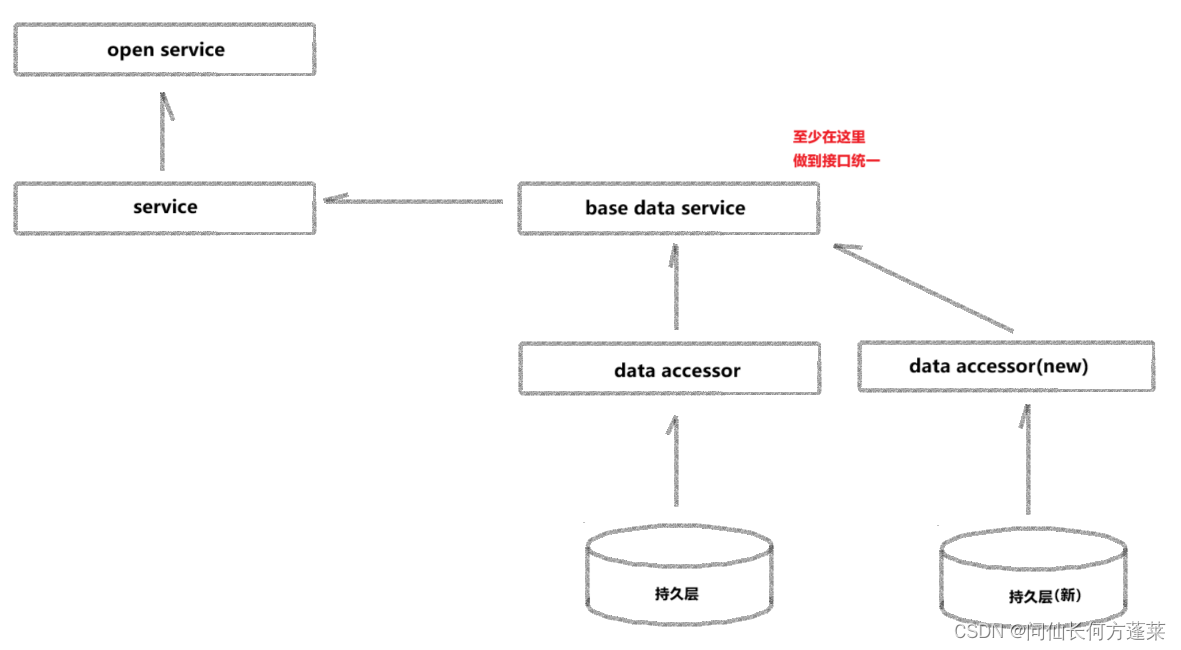 - 归档数据使用场景验证:需要验证所有使用数据的业务场景,至少在基础数据服务阶段可以返回一样的数据。如果对业务实现修改幅度较大,可以不用纠结接口的统一
- 归档数据使用场景验证:需要验证所有使用数据的业务场景,至少在基础数据服务阶段可以返回一样的数据。如果对业务实现修改幅度较大,可以不用纠结接口的统一 - 双写验证:验证对两个数据源可以随意写入,验证对老持久层增删改后新持久层可以同步
§4.4 确认归档数据范围 & 确认归档方案(快速归档可以直接从这里开始)
确认现存环境(主要用于评估业务场景覆盖的成本)
已有环境:db、mongo、es
已接入:db、mongo
可以搭建、接入:oss
估算归档数据范围的方法
估算步骤
- 统计当前最大id,有的时候同时也是全表数据量
- 统计保留 2/3/4/6/12 个月数据时(不同的档位),右边界的id 和 剩余数据量
- 单月期望数据增量 = 保留3个月剩余数据量 - 保留2个月剩余数据量,再用 4-3 个月核算
- 半年期望数据增量 = 单月期望数据增量 * 6
- 半年后期望数据量 = 剩余数据量 + 半年期望数据增量
- 最后结合业务场景、迁移方式,决定选择哪个档位(此时业务场景其实很简单了,基本都是简单索引查询)
可以按下表进行整理,定位 id 时参考下面 sql,注意边界的开闭(这个过程容易眼瞎,注意缓解)
select * from table_name where id<154408259 order by 1 desc limit 10
如果遇到无 create_time 的数据,大概率是扩展表,可以使用主表数据
 最后,结合各档位数据决定迁移的数据范围,按下表进行总结
最后,结合各档位数据决定迁移的数据范围,按下表进行总结
| 表 | 保留月数 | 保留量 | 截止id | 半年量 |
|---|---|---|---|---|
§4.5 迁移工具与方案
数据迁移的本质就是数据的复制,只有主动拉数和被动接受两个大方案,二者之间只是封装范围不同
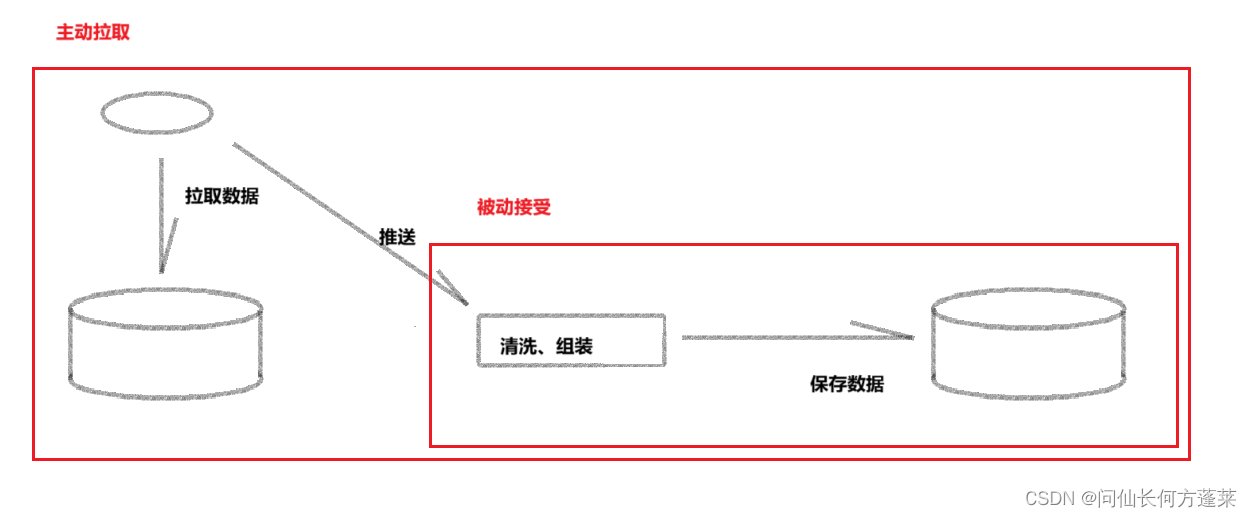
可选现成的 dts 工具(推荐),如阿里云的 dts,相关文档点这里
可以 组内自研(推荐),按正常需求开发
可以二方库自研(有条件时推荐,可以算部门kpi),按以下脉络开发
- 完善权限申请系统,用于二方库获取各业务侧数据源权限
- 对接各主流数据源,实现读写
- 完成对接简单字段映射、edi功能,或直接对接业务侧指定服务的驱动
- 完成监控、报告、速率调节、断续等功能(重要)
§4.6 生成归档迁移执行计划
按下表梳理
| 表 | 保留月数 | 截止id | 迁移目的 | 迁移技术 | 清洗/筛选 | 迁移控制 |
|---|
-
数据筛选:主要针对过滤掉某些不需要归档的字段。可以但是完全不建议直接横向过滤掉某条数据,尤其对应的主数据还在的情况下
-
数据清洗:主要是建立宽表过程中需要将散布在多处的信息整合为一行宽表数据
-
迁移控制
- 时机控制:在不影响业务的前提下,灵活控制,但要注意避开业务高峰期,夜间批量定时任务,和对数业务
- 速率控制:严禁无睡眠死循环处理,可以考虑舱闭+漏桶,low一些可以用窗口+睡眠控制,在有需求的场景下可以增加速率控制策略(数据擦除时比较必要)
§5 迁移执行阶段
只需要注意对现有业务的影响,控制速率即可
即使迁移出了问题,因为源数据没有删除,因此可以原地重试
迁移过程,如果是自研的,可以考虑完善报告机制,包括如下内容
- 进度、批次信息的统计
- 异常数据 id 的记录
§6 验证阶段
数据量验证:不要纠结于 count,可以从多个途径对照
- 迁移工具迁移任务的统计
- 归档 schema 信息(table_rows)的对比
- id 范围对照
可读性验证:业务场景覆盖阶段已经验证
归档后效率验证:直接通过访问工具或者在环境上验证均可
归档数据使用场景验证:业务场景覆盖阶段已经验证,在迁移后,还需要有一次验证。
准确性验证:不是必要步骤。 - 完整验证:对数任务,完整爬表对数,同时进行数据量验证,工作量极大
- 随机验证:主要用来验证迁移逻辑是否正确,在迁移的刚开始或者进行中,抽取若干数据,对比两个数据源中信息是否齐全正确。只能证明迁移逻辑是对的,但不能证明所有被迁移的数据都是对的
双写验证:业务场景覆盖阶段已经验证
§7 擦除阶段
前提:务必做完业务场景覆盖后的验证和归档迁移后的验证
擦除阶段只有单表 drop 的场景(非db也类似),只需要做好进度控制
- 不能影响原数据源 tps
- 速率不宜过快,不宜集中操作
- 先擦除轨迹数据,后擦除业务主数据
擦除速率定制
- 推荐删除速率 1000 - 24000 /min
- 推荐操作速率 < 12 /min
- 推荐删除数据量 < 1000 /批次
删除速率 = 每批次删除量 * 删除操作频率